node-problem-detector介绍

node-problem-detector是一个收集节点异常的组件,目标是使上层控制面对节点异常可见。在kubernetes集群中当前控制层面对节点异常的感知还比较薄弱,对于一些节点异常情况不能感知到,而这些异常问题往往会影响pod的运行。如当某节点pod网络异常时,kubernetes任然可以把相关pod调度到此节点,此时新创建的pod往往不可用。所以社区引入node-problem-detector来补充这一不足。node-problem-detector在每个节点上运行检测节点问题并将其报告,使各种节点问题对集群中的上层可见。
原理介绍
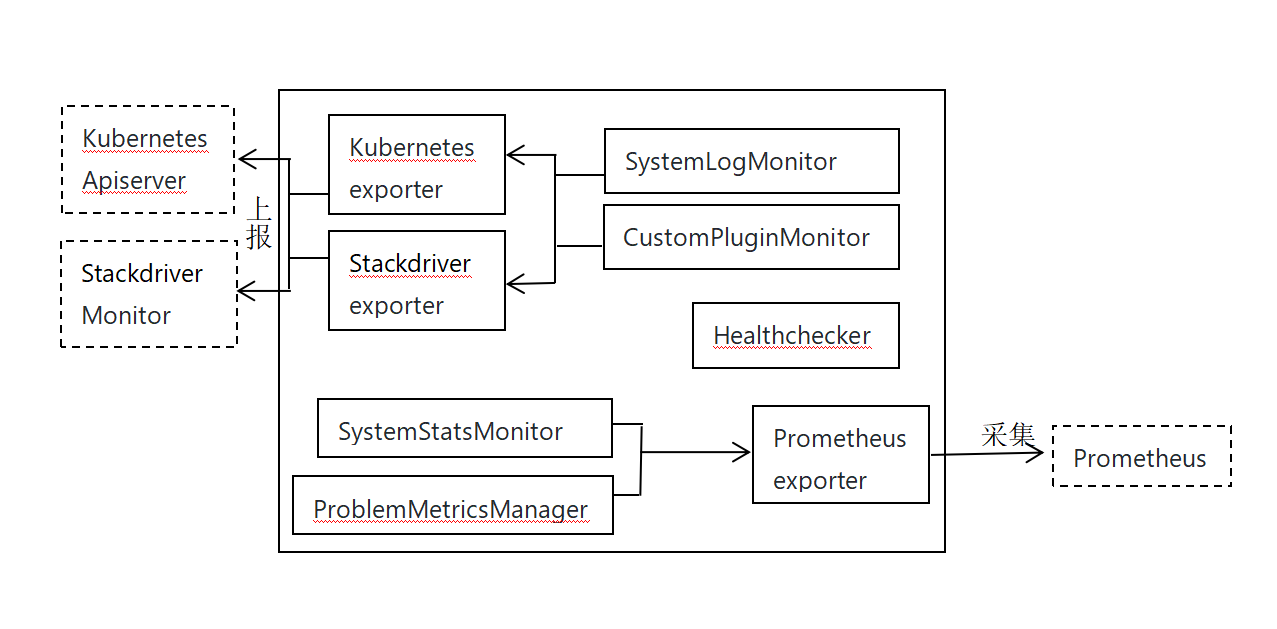
node-problem-detector主要包括“Monitor”和“Exporter”两大类型功能组件。“Monitor”类组件负责异常问题检测或指标数据采集,“Exporter”类组件负责向上对接控制层面进行数据上报。其中SystemLogMonitor和CustomPluginMonitor检测到的异常或指标可通过Kubernetes exporter或Stackdriver exporter分别上报到kubernetes apiserver 或Stackdriver Monitor。而SystemStatsMonitor和ProblemMetricsManager的监控指标数据通过Prometheus exporter暴露,进而可以通过Prometheus采集到相关数据。
主要模块介绍
Monitor
node-problem-detector包括SystemLogMonitor、SystemStatsMonitor和CustomPluginMonitor 3种monitor来分别检测不同类型的问题,详细类型参考:
| Monitor类型 | 说明 |
| SystemLogMonitor | 根据与设定的规则监控日志来检测问题,目前可以配置的日志有系统日志、kubelet日志、docker日志、containerd日志。 |
| SystemStatsMonitor | 监控和节点健康相关的监控指标。 |
| CustomPluginMonitor | 根据用户自定义检测脚本来检测。 |
Exporter
Exporter的作用是把检测到的问题或数据上报给相应后端。node-problem-detector目前提供三种Exporter:
| Exporter类型 | 说明 |
| Kubernetes exporter | 上报问题到Kubernetes API server:临时问题以Events形式上报; 永久问题以Node Conditions形式上报。 |
| Prometheus exporter | 上报节点的监控指标到Prometheus。 |
| Stackdriver exporter | 上报问题和监控指标到Stackdriver Monitoring API. |
Healthchecker
Healthchecker负责node-problem-detector运行节点的kubelet和容器运行时的健康检查功能,并在检查出异常后进行重启造作。
ProblemMetricsManager
node-problem-detector检测问题的指标数据,如某个类型问题发生的次数,某个异常问题是否影响了节点。
部署
(1)部署node-problem-detector
添加node-problem-detector repo:
[root@master ]# helm repo add deliveryhero https://charts.deliveryhero.io/
安装 node-problem-detector
[root@master ]# helm install --repo https://charts.deliveryhero.io/ npd node-problem-detector
NAME: npd
LAST DEPLOYED: Mon Jun 27 13:39:19 2022
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
To verify that the node-problem-detector pods have started, run:
kubectl --namespace= default get pods-l"app.kubernetes.io/name=node-problem-detector,app.kubernetes.io/instance=npd"
[root@master ]#
查看node-problem-detector已运行于各个节点:

模拟内核出现异常,在日志中写入内核异常的日志:
[root@node1 ]# sh -c "echo 'kernel: BUG: unable to handle kernel NULL pointer dereference at TESTING' >> /dev/kmsg"
查看事件,可以看到node-problem-detector已检测到kernel BUG。

自定义检测扩展实践
node-problem-detector当前支持基于日志匹配规则的异常检测;kubelet运行异常检测;容器运行时异常检测;ntp服务未启动检测和conntrack表超过90%的检测等问题检查项。虽然node-problem-detector已内置了一些问题检测,但实际使用时候往往还不能满足用户的需求,需要自定义检测进行扩展。以下以“NTPProblem”为例介绍自定义检测是如何集成到node-problem-detector中的。
(1)配置添加
通过前文可知node-problem-detector提供了CustomPluginMonitor支持用户添加自定义脚本来检测相关的问题。启动时需要在启动参数中添加 --config.custom-plugin-monitor配置:
node-problem-detector - --config.custom-plugin-monitor=/config/custom-plugin-monitor.json ... ..
custom-plugin-monitor.json内如如下:
| { "plugin": "custom", "pluginConfig": { "invoke_interval": "30s", "timeout": "5s", "max_output_length": 80, "concurrency": 3, "enable_message_change_based_condition_update": false }, "source": "ntp-custom-plugin-monitor", "metricsReporting": true, "conditions": [ { "type": "NTPProblem", "reason": "NTPIsUp", "message": "ntp service is up" } ], "rules": [ { "type": "temporary", "reason": "NTPIsDown", "path": "./config/plugin/check_ntp.sh", "timeout": "3s" }, { "type": "permanent", "condition": "NTPProblem", "reason": "NTPIsDown", "path": "./config/plugin/check_ntp.sh", "timeout": "3s" } ] } |
从配置文件中可以看出实际检测时node-problem-detector调用的脚本是“check_ntp.sh”,目录在镜像的/config/plugin/目录中,内如如下:
| #!/bin/bash # This plugin checks if the ntp service is running under systemd. # NOTE: This is only an example for systemd services. readonly OK=0 readonly NONOK=1 readonly UNKNOWN=2 readonly SERVICE='ntpd.service' # Check systemd cmd present if ! command -v systemctl >/dev/null; then echo "Could not find 'systemctl' - require systemd" exit $UNKNOWN fi # Return success if service active (i.e. running) if systemctl -q is-active "$SERVICE"; then echo "$SERVICE is running" exit $OK else # Does not differenciate stopped/failed service from non-existent echo "$SERVICE is not running" exit $NONOK fi |
因为脚本中直接使用了systemctl命令,因此当已pod形式运行在节点中时node-problem-detector镜像中需要安装好此命令否则检测脚本将不可用,同时为了能够和宿主机的systemd通信,需要把宿主机上的“/var/run/dbus”和“/run/systemd”目录挂载进node-problem-detector容器中。
(2)结果验证
如宿主机中ntp异常即可在kubernetes中看到上报信息:
在node.status.conditions中上报信息如下:
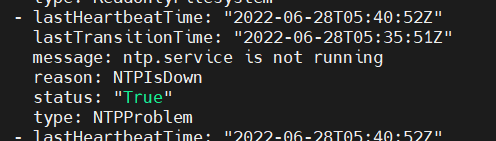
event形式上报信息如下:

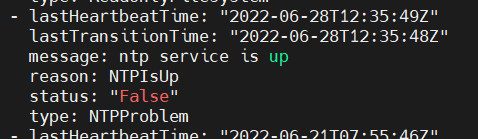
节点开启ntp服务后,node.status.conditions上报信息如下:
总结
在kubernetes集群中节点异常对上层的可见性是非常必要的,这种感知能力在原生的集群中还比较薄弱。node-problem-detector对这一能力进行了加强,同时基于用户自定义扩展机制使得node-problem-detector可检测的节点问题很丰富。
声明:本网转发此文章,旨在为读者提供更多信息资讯,所涉内容不构成投资、消费建议。文章事实如有疑问,请与有关方核实,文章观点非本网观点,仅供读者参考。









